(Don't read this page. It is a work in progress for a Fall'19 graduate automated SE subject at NC State. Come back in mid-October!)

Start1.preface2.why se 4 ai? 3.tools 4.ethics: how |
ToolsbaselinesData mining: discretization basic advanced Optimizers: landscapes basic advanced optimizing+data mining Theorem provers: basic advanced |
Processrequirementscollect cleanse label train eval deploy monitor |
Codeconfigtests |
Exercises12 3a 3b 3c 3d 4 |
But Why Study SE for AI?
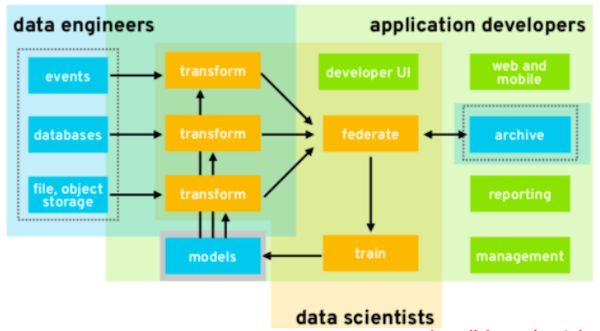
It is timely to talk about SE for AI. AI software is still software and all software (be it AI software, or otherwise) needs installation, configuration, maintenance, interfacing to other software, testing, certification, user support, usability additions, and packaging (for distribution). As shown below, Bill Benton from Redhat reports that that when we look at the data mining pipelines used to distribute and scale AI tools, there is much overlap between the activities of data scientists and more traditional activities like data engineer and application developer. That is, AI software needs care and feeding by software engineers.
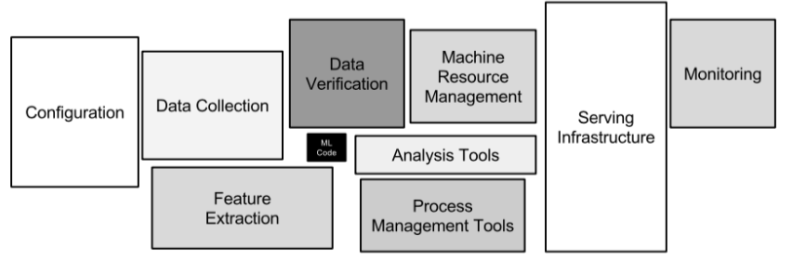
Another reason to explore SE for AI is that most “AI software” is not about AI. David Sculley offers the following diagram showing the size (in lines of code) of Google’s software suite. Note how small is the AI box (shown in black), buried away in the middle of all the other software.
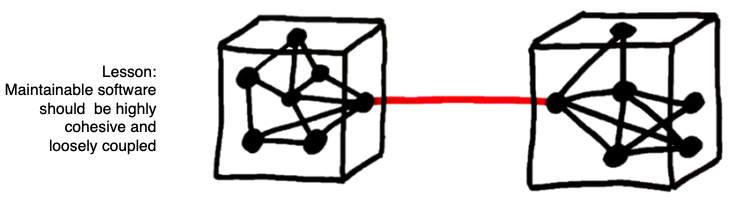
Since AI software is still software, it follows that poor software engineering leads to poor AI. Again, David Sculley offers us an example of this. He reports that Google’s machine learning developers used all of the attributes in Google’s data dictionaries to learn predictive models about browsing habits. This lead to problems since any subsequent change in the data dictionary meant that all the data mining had to be done, all over again. In software engineering terms, Google had introduce technical debt (i.e. something that will consume maintenance money at some future date) by violating principles of coupling and cohesion. Maintainable systems are loosely coupled (but internally, tightly cohesive). Google’s classifiers, on the other hand were tightly coupled with their data dictionaries. A better design, that would have looser coupling would have been to apply some sort of feature weighting to the data, and only connect to the least features that were most influential.
While poor software engineering can lead to problems with the AI, the good news is that better SE can lead to better AI. For example, many industrial data scientists make extensive use of the Python scikit-learn toolkit data mining package. Started in 2007 as a Google Summer of Code project by David Cournapeau, numerous releases have appeared following a (approximately) three month cycle, and a thriving international community has been leading the development. At the time of this writing, over the last month, this software has been maintained and extended by dozens of authors, spread around the planet (specifically, excluding merges, 50 authors have pushed 119 commits to master and 119 commits to all branches to make changes thousands of lines of code in 279 files). All this is possible since scikit-learn uses state-of-the-art open source software engineering methods (continuous integration, cloud-based testing with Travis CI, git, github, etc etc).
Since good SE can lead to better AI, we devoted many chapters of this book to industrial data mining pipelines. Recently we reversed engineered a nine-step pipeline for industrial machine learning. For simplicity’s sake, we draw it as steps that run left to right (but in reality, AI is an agile process where we jump around these steps, as required):

We also surveyed many industrial data scientists to understand how much time they spend on different parts of this pipeline:
| hrs/week (mean, approx) |
||
|---|---|---|
| requirements | 4.4 |  |
| collection | 4.7 | |
| cleaning | 4.5 | |
| labelling | 2.9 | |
| feature engineering | 4.6 | |
| model training | 5.4 | |
| evaluation | 3.8 | |
| deployment | 5.1 | |
| monitoring | 2.6 | |
One interesting feature about the above histogram is that most “data mining” is not about mining the data. We say this since, in a 35 hour work week, only half a day (5.4.hours) was spent in training. This is interesting since most data mining textbooks only talk about training. Hence, if we are going to talk SE for AI, there is a pressing need to discuss all the work that fills up the other four days of the week.